
Closures in SQL?
Through my daily blog reading, I came across this post making an argument for not using the SQL "IN" clause as a substitute for a JOIN. I saw something familiar and interesting in one of the examples listed, and will try to demonstrate it here.
The right-hand side of an "IN" clause is simply a set of values. This can be provided by means of a comma-separated list of literals, or by a SELECT statement.
To demonstrate the syntax, consider the following table:
| Day | Vehicle | Miles |
|---|---|---|
| Mo | Bike | 50 |
| Tu | Car | 85 |
| We | Truck | 33 |
| Th | Bike | 74 |
| Fr | Car | 23 |
If I wanted only the miles for trips taken by Cars and Bikes, then I could provide those literals as:
SELECT Vehicle, Miles
FROM TripLog
WHERE Vehicle IN ( 'Car', 'Bike' )
Or, I could store the values within fields of another table, and SELECT them (the caveat is that I can only select a single field in my subquery):
| Type | MPG | Fuel |
|---|---|---|
| Car | 28.1 | Gasoline |
| Bike | 32.4 | Gasoline |
| Rocket Ship | 0.0000000421 | Hydrazine |
SELECT Vehicle,
Miles
FROM TripLog
WHERE Vehicle IN ( SELECT Type
FROM PreferredVehicle )
The point that the other blogger was trying to make was that you might just want to use a simple INNER JOIN. But, I'm not here to argue that point. Instead, I'd like to expand on a path that he just touched on in a counter example.
Suppose that I mistyped the subquery used in the "IN" clause, and used "Vehicle" instead of "Type" for the selected column:
SELECT Vehicle,
Miles
FROM TripLog
WHERE Vehicle IN ( SELECT Vehicle
FROM PreferredVehicle )
The result is that I would get all rows returned, including the one for "Truck". This is despite the fact that there is no column in [PreferredVehicle] called "Vehicle", and that "Truck" doesn't appear anywhere in the [PreferredVehicle] table. Why?
Let's first look at another query that sort of demonstrates what is happening:
SELECT 'Car'
FROM PreferredVehicle
The result is that you'll get one row returned in the resultset for every row in the table, with each returned row containing only the value "Car". This is because a SELECT FROM query evaluates for every row in the FROM clause (filtered by a WHERE clause, if present). And, since we're only selecting a literal string and no other fields from the table, then the output will however many rows there are in [PreferredVehicle] with each row containing only that string value. Simple, right?
But how does this explain why all rows were returned when the subquery used a column name that doesn't even exist in the subquery's table?
From the language point of view, the subquery from the "IN" clause is executing within the context of the outer query. An interesting side effect is that the subquery has access to all of the "locals" in the outer query. That is, if you think of this executing row by row, then think of the subquery having access to the columns in each row returned by the outer query. That is, you have a Closure! Sort of... (Since you can think of the subquery as being sort of like an anonymous function defined within another function)
So, if you're still imagining this row-by-row evaluation of the subquery, then you can see how the "Vehicle" from each row in the outer query is simply selected as the output of the subquery -- much like when the literal string was used. And, because the "Vehicle" from the row of the outer query matches a value in the set returned from the subquery (it actually matches every value in the set that is returned for that row), then that WHERE clause predicate is satisfied, and the row from the outer query is returned.
"Truck" is in the set ["Truck", "Truck", "Truck"]
"Car" is in the set ["Car", "Car", "Car"], etc, etc.
As a developer, knowing and exploiting this behavior will likely scare the hell out of your DBA's if and when they perform code reviews. But, it also allows you to do some "elegant" things in your code. And some unexpected things, too, if you're not careful.
For example, let's try to select [TripLog] entries for vehicle types where I was able to drive at least one day for under $5.00. I'll use an amazingly cheap current gasoline price of $2.90 per gallon in this calculation, grabbing the Miles from the [TripLog] row, and the MPG from the [PreferredVehicle] table.
You would think that the following query would do the job of building a set of Vehicle Types that match our criteria, and then using that set as the right-hand side of the "IN" clause.
SELECT Vehicle, Day
FROM TripLog
WHERE Vehicle IN ( SELECT Type
FROM PreferredVehicle
WHERE ( 2.90 * Miles / MPG ) < 5.00 )
As such, I would expect the query to output the following:
Mo Bike 50
Tu Car 85
Th Bike 74
Fr Car 23
because both Bike and Car have days where the cost of the trip were under $5.00, so therefore, I would think that all Bike and Car rows should be returned. Truck is not in [PreferredVehicle], so, it would not be returned.
However, here is the actual output:
Mo Bike 50
Fr Car 23
Yes, I got the rows where the trip price was under $5.00. But, the query actually filtered out all rows where the price exceeded $5.00.
That certainly doesn't seem correct from a set-based point of view, but is very consistent to a Closure-based point of view. When evaluated row-by-row, the [TripLog] entries with too many miles will fail the "IN" clause test, and will therefore, not be included in the output.
In reality, the results are exactly the same as if we had used an INNER JOIN with a WHERE clause:
SELECT Day,
Vehicle,
Miles
FROM TripLog AS TL
JOIN PreferredVehicle AS PV
ON TL.Vehicle = PV.Type
WHERE ( 2.90 * TL.Miles / PV.MPG ) < 5.00
But, the execution plans are different. In fact, despite all of the negative comments said about using INNER JOINs versus IN clauses, the "Closure" version is less than half the cost of the JOIN/WHERE version of the query... which totally surprised me.
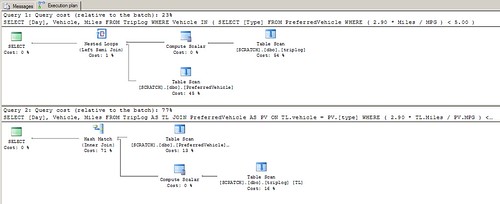
Closures in SQL... Who knew!!??!

|